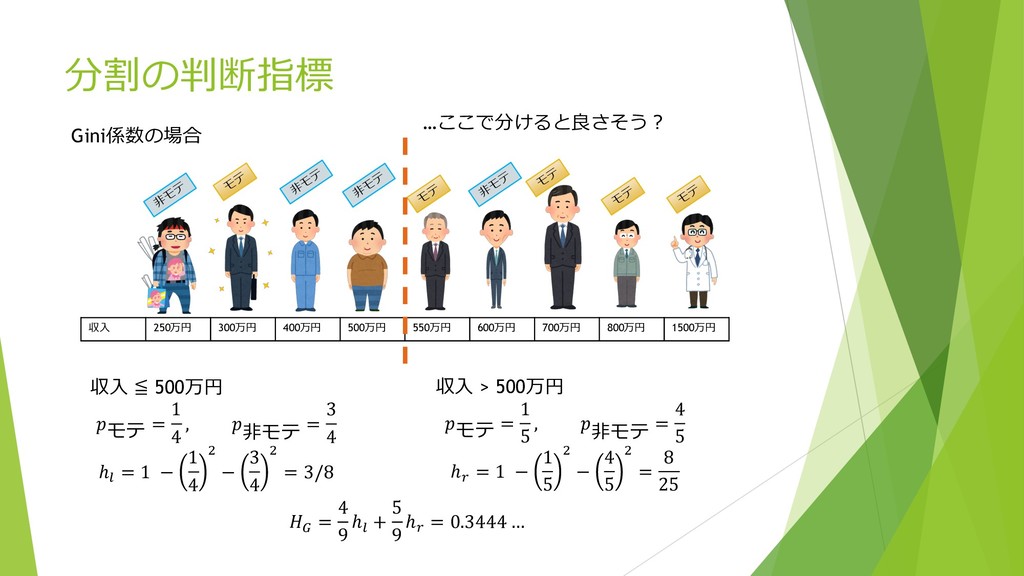
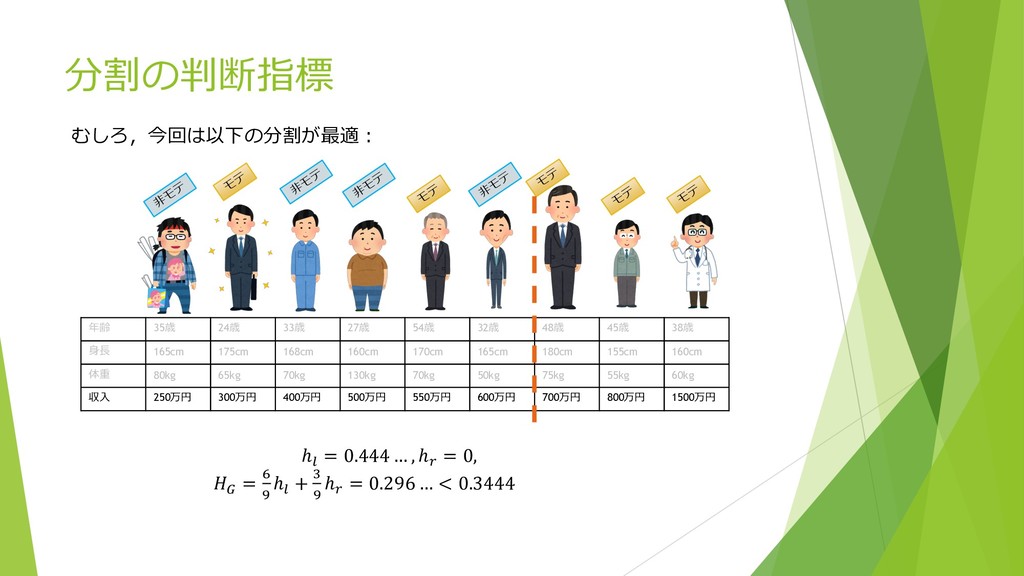
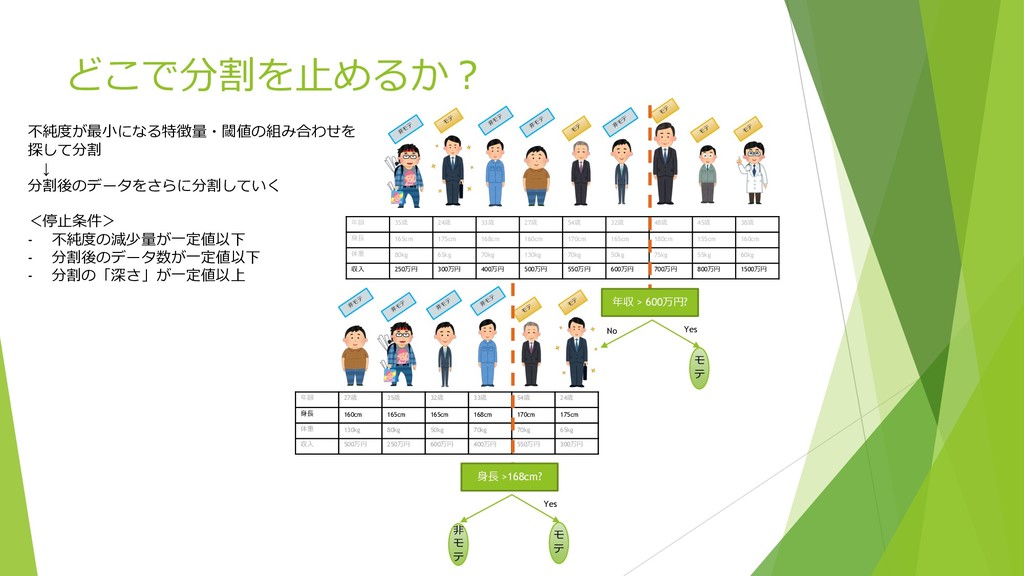
⾮ モ テ モ テ モ テ ⾮ モ テ ⾮ モ テ 収⼊ 250万円 300万円 400万円 500万円 550万円 600万円 700万円 800万円 1500万円 収⼊ ≦ 500万円 モテ = 1 4 , ⾮モテ = 3 4 ℎ; = 1 − 1 4 , − 3 4 , = 3/8 収⼊ > 500万円 モテ = 1 5 , ⾮モテ = 4 5 ℎ> = 1 − 1 5 , − 4 5 , = 8 25 A = 4 9 ℎ; + 5 9 ℎ> = 0.3444 … Gini係数の場合 …ここで分けると良さそう︖
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}